
지난 게시글에 연재되는 도전기 4편입니다 . https://itadventure.tistory.com/544
파이스크립트 도전기(3) - 판다스로 csv 읽고 표로 출력하기
지난 게시글에 연재되는 도전기 3편입니다 : https://itadventure.tistory.com/543 파이스크립트 도전기(2) - 인구변화 그래프 지난 게시글에 이어 파이스크립트 2번째 도전기입니다. 지난 게시글 : https://ita
itadventure.tistory.com
오늘은 판다스로 csv 데이터를 읽어
파이플롯(pyplot) 그래프로 출력하는 부분을 도전!해보겠습니다.
CSV 파일을 찾아보다
사실 적당한 csv 데이터를 찾는 일이 만만치 않더라구요.
여기저기 뒤져보던 중 캐글( www.kaggle.com )이 유용한 연습용 데이터가 많아 이쪽을 선정하였습니다.
캐글에는 데이터 세트(Datasets)라는 메뉴가 있는데 여기에서 유용한 csv 데이터를 다운받을 수 있는데요.
URL 주소는 아래와 같습니다.https://www.kaggle.com/datasets
Find Open Datasets and Machine Learning Projects | Kaggle
Download Open Datasets on 1000s of Projects + Share Projects on One Platform. Explore Popular Topics Like Government, Sports, Medicine, Fintech, Food, More. Flexible Data Ingestion.
www.kaggle.com
그러면 여러 데이터세트가 나열되는데요. 영어로 나옵니다만.

우리에게는 훌륭한 구글 번역이 있기 때문에 겁먹을건 없습니다 :)
화면 아무데나 마우스 우클릭 - 한국어로 번역 메뉴를 선택해 주시면, ( 크롬 브라우저에서 )
약간 어색한 번역도 있긴 하지만, 친숙한 한국어가 표시됩니다.

어떤 데이터를 사용해 볼까 찾아보다 BigBasket 전체 제품 목록 데이터를 사용해 보기로 했습니다.
인기데이터는 언제든지 바뀔 수 있기 때문에 미리 URL을 메모해 놓도록 할까요 ? :)
https://www.kaggle.com/datasets/surajjha101/bigbasket-entire-product-list-28k-datapoints
BigBasket Entire Product List (~28K datapoints)
Analyzing BB Products and their performance across
www.kaggle.com
데이터셋의 중간 즈음을 살펴보면 데이터의 용량과 각 항목에 대한 안내, 그리고 각 항목에 대해
한글 자동 번역이 100% 깔끔한 편은 아니지만 어느 정도 이해가 가능한 수준으로 보이는군요.
특히 부가적인 설명이 붙어 있어서 좋은 것 같습니다.
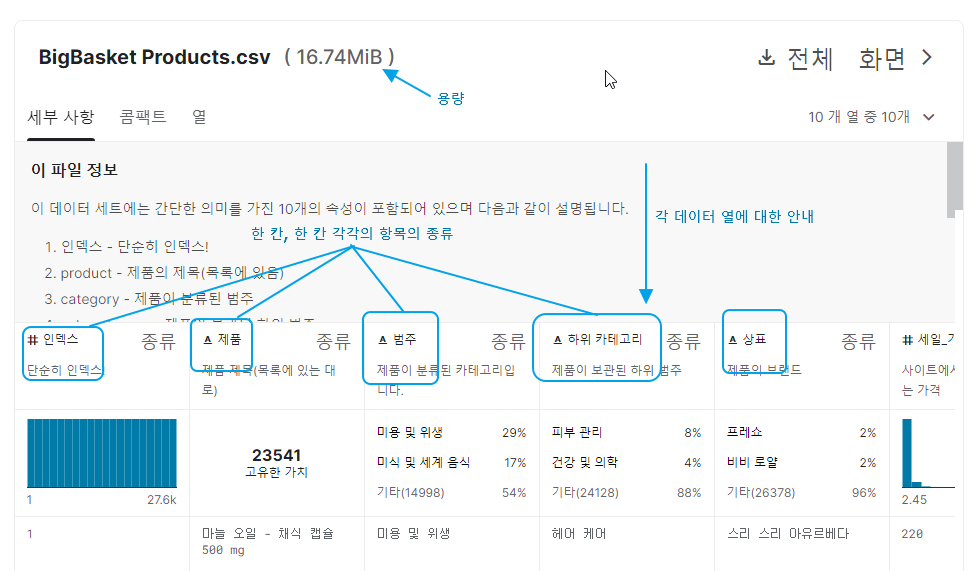
이 파일은 압죽버전으로 제공되는데요, 압축을 풀면 용량이 16Mbyte 정도 됩니다.
소량의 데이터만 간단히 테스트할 용도라 200줄 정도로 줄였더니 112kbyte 정도로 줄었는데요.
크레이의 홈페이지 계정에 올려놓았고, URL은 아래와 같습니다.
https://dreamplan7.cafe24.com/pyscript/BigBasket_Products_200.csv
CSV 파일을 읽어볼까?
이제 이 데이터를 지난번처럼 파이스크립트에서 불러와 표로 구성해보도록 하겠습니다.
<html>
<head>
<title>
Read CSV with Pandas using PyScript
</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
<style type="text/css">
table.dataframe th {
background-color: #EA6153 !important;
color: white !important;
text-align:center !important;
padding: 5px 15px;
font-size:9pt !important;
}
table.dataframe td {
color: black !important;
text-align:center !important;
padding: 5px 15px;
font-size:9pt !important;
}
table.dataframe tr {
background-color: #FFFFFF !important;
}
table.dataframe tr:nth-child(odd) {
background-color: #E9E9E9 !important;
}
</style>
<py-env>
- pandas
</py-env>
</head>
<body style="padding:20px;">
<h2>파이스크립트에서 판다스(Pandas)로 CSV 읽기</h1>
<div id="csv" style="margin-top:10px"></div>
<py-script>
import pandas as pd
from pyodide.http import open_url
# URL 에서 csv 데이터를 읽어 판다스 배열로 변환합니다.
df = pd.read_csv(open_url("http://dreamplan7.cafe24.com/pyscript/BigBasket_Products_200.csv"))
# 출력할 HTML 요소를 선택
csv = Element('csv')
# 해당 HTML 요소에 결과를 출력합니다.
csv.write(df)
</py-script>
</body>
</html>
200개의 결과물이 쫘~악 펼쳐질 줄 알았는데 어라? 이게 웬 일입니까?
파이썬이 너무 똑똑한 걸까요? 중간은 과감하게 생략하고 앞의 5건과 뒤의 5건만 불러와 버리는군요 ㅎ..

찾아보니 모든 행을 출력하려면 아래 옵션 설정이 추가되어야 하더군요.
pd.set_option('display.max_rows', None)해당 옵션을 중간에 추가한 다음 다시 실행해보니
:
# URL 에서 csv 데이터를 읽어 판다스 배열로 변환합니다.
df = pd.read_csv(open_url("http://dreamplan7.cafe24.com/pyscript/BigBasket_Products_200.csv"))
pd.set_option('display.max_rows', None)
# 출력할 HTML 요소를 선택
csv = Element('csv')
:
200개의 행이 연이어 쫘~악 나열되는군요. 이제 좀 마음에 듭니다.

뽑아낼 데이터는 바로 이것!
이제 여기서 어떤 항목을 그래프로 추출해볼지 생각을 해보았습니다.
평점이 가장 무난하므로 브랜드별 평점 평균이 어떤지를 대상으로 하기로 했습니다.
먼저 브랜드별 평점 평균을 구할 수 있도록 소스를 구성해야겠지요.
SQL이해도가 높은 편이라, 친숙한 groupby 라는 명령어를 사용하기로 했는데요,
사용법은 아래와 같습니다. 그룹을 기준으로 항목1, 항목2 등을 그룹화해서 평균, 합계 등을 계산해 그룹변수에 넣습니다.
그룹변수 = df[['항목1', '항목2']].groupby(df['그룹'])
소스에서는 아래 행을 추가했습니다.
:
# URL 에서 csv 데이터를 읽어 판다스 배열(데이터 프레임)으로 변환합니다.
df = pd.read_csv(open_url("http://dreamplan7.cafe24.com/pyscript/BigBasket_Products_200.csv"))
# 평점을 추출대상으로 브랜드별로 그룹화
df_group = df[['rating']].groupby(df['brand'])
# 모든 행을 출력하도록 옵션을 설정합니다.
pd.set_option('display.max_rows', None)
:
그리고 결과를 출력하는 부분을 변경한 다음,
:
csv.write(df_group.mean())
결과를 확인해 보았습니다. ( 한번에 성공한 것은 아닙니다. 여러번의 오류메시지를 확인하고서 된것이지요 :) )
와우~ 브랜드별로 평점에 대한 평균이 나타난 것을 확인할 수 있었습니다.
참고로 NaN 은 Not a number 의 약어로 숫자가 아니라는 의미입니다. 평점란이 공란이더라구요,
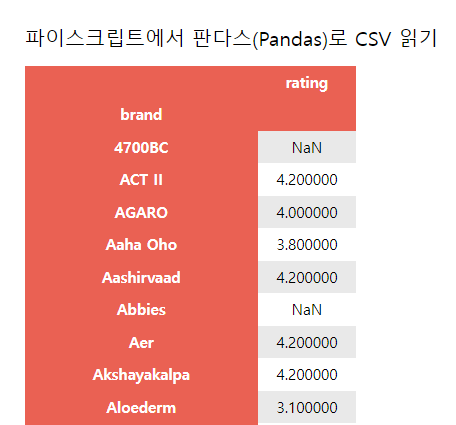
NaN 는 그래프에서 사용하기 곤란하니 0으로 바꿔버리기로 했습니다.
df_group 변환 부분을 아래 명령어로 변경하니 NaN 부분이 0으로 채워지더라구요,
df_group = df[['rating']].fillna(0).groupby(df['brand'])
그래프로 구성, 마음에 드는데!
한번에 되지는 않아 어느정도 삽질을 한 다음에 아래와 같은 결과를 만들었는데요. ( 이러면서 실력이 느는 겁니다 ㅎㅎ )

평점순으로 정렬을 했는데 평점이 낮은 순서가 먼저 나오더라구요.
그래프에서는 Y 축은 아래에서 위로 순서가 나열되기 때문에 Y축을 바꿔서 표시해주는 명령을 또 하나 알아내에 적용했습니다.
plt.gca().invert_yaxis()
거두 절미하고 최종 소스 공개합니다!
<html>
<head>
<title>
Read CSV with Pandas using PyScript
</title>
<link rel="stylesheet" href="https://pyscript.net/alpha/pyscript.css" />
<script defer src="https://pyscript.net/alpha/pyscript.js"></script>
<style type="text/css">
table.dataframe th {
background-color: #EA6153 !important;
color: white !important;
text-align:center !important;
padding: 5px 15px;
font-size:9pt !important;
}
table.dataframe td {
color: black !important;
text-align:center !important;
padding: 5px 15px;
font-size:9pt !important;
}
table.dataframe tr {
background-color: #FFFFFF !important;
}
table.dataframe tr:nth-child(odd) {
background-color: #E9E9E9 !important;
}
</style>
<py-env>
- pandas
- matplotlib
</py-env>
</head>
<body style="padding:20px;">
<h2>파이스크립트에서 판다스(Pandas)로 CSV 읽기</h1>
<div id="pltdiv"></div>
<div id="csv" style="margin-top:10px"></div>
<py-script>
import pandas as pd
from pyodide.http import open_url
# URL 에서 csv 데이터를 읽어 판다스 배열(데이터 프레임)으로 변환합니다.
df = pd.read_csv(open_url("http://dreamplan7.cafe24.com/pyscript/BigBasket_Products_200.csv"))
# 평점을 추출대상으로 브랜드별로 그룹화
df_group = df.fillna(0).groupby('brand')[['rating']].mean().sort_values(by='rating', ascending=False)
#df_group.columns = ['brand', 'rating']
# 모든 행을 출력하도록 옵션을 설정합니다.
pd.set_option('display.max_rows', None)
# 출력할 HTML 요소를 선택
csv = Element('csv')
# 산출된 평점의 평균울 출력
csv.write(df_group)
import matplotlib.pyplot as plt
plt.rcParams.update({'font.size': 7})
fig = plt.figure(figsize=(5, 20))
plt.plot(
df_group['rating'].to_list(),
df_group.index.to_list(),
label='Rating of Brand' )
plt.gca().invert_yaxis()
pltdiv = Element('pltdiv')
pltdiv.write(fig)
</py-script>
</body>
</html>결과물


이 결과는 크레이의 홈페이지인 아래 URL에서도 확인하실 수 있습니다.
http://dreamplan7.cafe24.com/pyscript/py5.html
마무~리
오늘은 파이스크립트에서 CSV파일을 읽은 다음,
데이터를 가공하여 브랜드별 평균을 산출하고 정렬한 다음에,
이를 그래프로, 표로 동시에 출력하는 부분을 다뤄보았습니다.
그래프의 Y 축을 정반대로 바꿀 필요가 있어 해당 부분도 수정했었지요.
양이 좀 있다 보니 글도 스크롤 압박이 좀 있군요.
필요하신 분께 도움이 되시길 바랍니다.
한주에 출발이 곧 다가오겠군요.
구독자 여러분 모두들 활력 얻기를 바랍니다.
긴 글 읽어 주신 분들께도 모두 감사드립니다.
다음 게시글 : https://itadventure.tistory.com/546
파이스크립트 도전기(5) - 브라우저에서 파이썬 인터프리터?
지난 게시글에 연재되는 도전기 3탄입니다. https://itadventure.tistory.com/545 파이스크립트 도전기(4) - csv 읽고 그래프 출력하기 지난 게시글에 연재되는 도전기 4편입니다 . https://itadventure.tistory...
itadventure.tistory.com