'파도'는 파이스크립트 도전기의 줄임말입니다.
지난 게시글에서 이어지는 내용입니다 : https://itadventure.tistory.com/553
파도!(12) - 무신 러닝? 머신러닝! - 리니어 리그레션 ( LinearRegression )
'파도'는 파이스크립트 도전기의 줄임말입니다. 지난 게시글까지는 파이스크립트에서 csv 로 된 데이터를 불러와 그래프로 표현하는 것이 중점적인 내용이었지요. https://itadventure.tistory.com/552 파
itadventure.tistory.com
지난 게시글에서 다루었던 머신 러닝예제에서 아쉬운 부분이 있었는데요.
새로운 데이터의 굴곡 부분은 기존 자료와 예측량이 꽤 차이가 나는 점이었습니다.
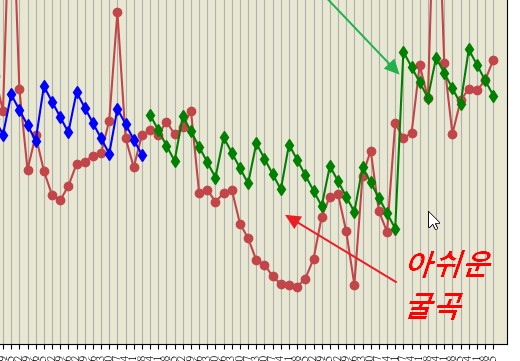
아래의 그림처럼 과거의 패턴을 답습한다고 생각되었는데요.
그저 이게 한계겠거니 생각했습니다.
그런데?
그래서 마지막으로 단순히 평균가격을 추가하면 조금이라도 적중율이 올라가지는 않을지 살펴보자 했지요.
그런데.. 어라? 그래프의 모양이..
거의 원본과 동기화되듯이 따라가는 사태가 벌어진 것이 아니겠습니까?!
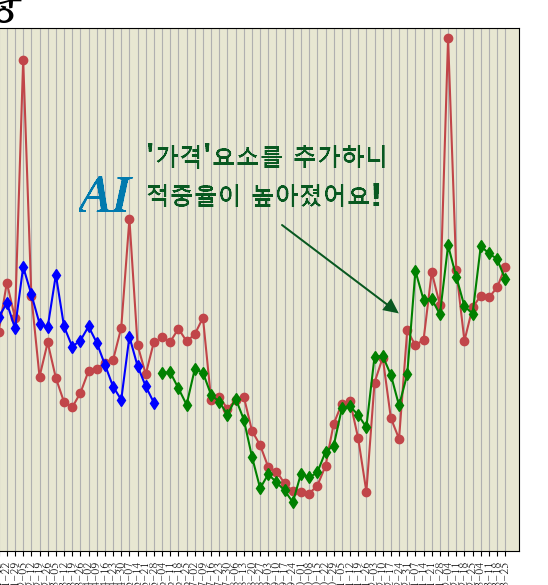
아주 정확한 것은 아니지만 동선의 형태가 상당히 유사한 것을 볼 수가 있었지요.
특히나 하단 굴곡 부분이 말이지요. 여태껏 한번도 나온 패턴같지도 않은데 말이지요.
머신러닝이 내부에서 수행하는 일은 자세히 알 수 없겠지만,
아마도 가격이 비싸면 매출량이 줄어들고, 가격이 저렴하면 매출량이 늘어나는게 아니었을까 추정해 보는 크레이입니다 :)
이번에도 지난주말에 익혔던 몇가지 기술을 가미해보았는데요.
우선 일부 변경된 부분 설명부터 드리고, 전체 소스 공개순으로 가보겠습니다.
평균가격 포함
이번에는 평균가격을 포함하기 위해 CSV 파일을 읽고 3개의 컬럼을 받아오도록 변경해 보았습니다.
AveragePrice 가 바로 제공된 데이터중 평균가격입니다.
# 판다스에서 csv 를 데이터 프레임으로 읽어옴
매출데이터 = pd.read_csv(open_url(
"http://dreamplan7.cafe24.com/pyscript/csv/avocado.csv"
))
# 3개 필드만 추려서 데이터 프레임을 다시 만듬
매출데이터 = 매출데이터[[
'Date',
'Total Volume',
'AveragePrice'
]]
각 컬럼의 이름 역시 모두 한글명으로 변경해주었구요.
매출데이터.columns = [
'날짜',
'매출량',
'평균가격'
]
그리고 날짜별로 ( 주 단위로 ) 그룹을 지을 때도 매출량은 그룹단위로 합산하여 합계를 구하고,
평균가격은 그룹단위로 합산하여 평균을 따로 산출하였습니다.
양쪽의 차이점을 보면 한쪽은 sum() 을 사용하고 한쪽은 mean() 을 사용하고 있는데요.
한쪽은 합계값를, 한쪽은 평균값을 구한다는 의미입니다.
주간매출_매출량=매출데이터.fillna(0) \
.groupby('날짜', as_index=False)[['매출량']].sum() \
.sort_values(by='날짜', ascending=True)
주간매출_평균가=매출데이터.fillna(0) \
.groupby('날짜', as_index=False)[['평균가격']].mean() \
.sort_values(by='날짜', ascending=True)
그리고 2개의 데이터 프레임을 하나로 합쳐주는데요.
이 때 사용하는 것이 판다스의 merge 메소드입니다.
on에 기재된 '날짜'를 기준으로 해서 자료를 합쳐주지요.
주간매출데이터=pd.merge(주간매출_매출량, 주간매출_평균가, on='날짜')
머신러닝에 자료를 넘겨주는 부분에서도
'평균가격' 항목을 넘겨주는 부분이 추가되었는데요.
주간매출데이터훈련_넘파이 = 주간매출데이터[['날짜(시간값)', '연도', '월', '일', '주', '평균가격']].to_numpy()
이 자료를 기준으로 해서, 훈련용데이터와 테스트데이터를 분리하게 됩니다.
훈련용데이터, 테스트데이터, 훈련용목표, 테스트목표 = \
train_test_split(
주간매출데이터훈련_넘파이,
주간매출데이터목표_넘파이,
random_state=100,
shuffle=False)
데이터 스케일링
위 자료를 이제 바로 머신러닝에 적용해도 되지만, 이번에는 '스케일화'라는 것을 적용해보도록 했습니다.
스케일화에 대한 수학적 이론을 사실 알 필요는 없습니다.
그것보다는 스케일화는 '데이터를 안정화'해주는 부분에 있는데요.
각각의 항목에 대한 비중이 공정되도록 그 값을 아래와 같은 형태로 변형시켜 줍니다.
원래의 값은 온데 간데 없이 말이지요.
[[-1.71835849 -1.04595272 -1.41158457 -1.3313997 -0.55786605]
[-1.69086476 -1.04595272 -1.41158457 -0.53634585 0.07839557]
[-1.66337102 -1.04595272 -1.41158457 0.258708 0.26613097]
[-1.63587728 -1.04595272 -1.41158457 1.05376184 0.32134727]
[-1.60838355 -1.04595272 -1.12143831 -1.67213706 -1.05566218]]싸이킷런 라이브러리의 StandardScaler 를 가져다 사용하면 쉽게 스케일화가 가능한데요.
아래는 훈련용데이터에 딱 맞춘 맞춤형 스케일러를 설정한 다음,
훈련용데이터를 스케일화한 데이터와 테스트데이터를 스케일화한 데이터를 산출합니다.
from sklearn.preprocessing import StandardScaler
스케일러 = StandardScaler()
스케일러.fit(훈련용데이터)
훈련용데이터_스케일 = 스케일러.transform(훈련용데이터)
테스트데이터_스케일 = 스케일러.transform(테스트데이터)그러면 원래 이런 모양이던 훈련용데이터가
[[1420329600.0 2015 1 4 1.3012962962962962]
[1420934400.0 2015 1 11 1.370648148148148]
[1421539200.0 2015 1 18 1.3911111111111112]
[1422144000.0 2015 1 25 1.3971296296296298]
[1422748800.0 2015 2 1 1.2470370370370372]]이렇게 바뀌어 버리는 기묘한(?) 현상이 일어납니다.
[[-1.71835849 -1.04595272 -1.41158457 -1.3313997 -0.55786605]
[-1.69086476 -1.04595272 -1.41158457 -0.53634585 0.07839557]
[-1.66337102 -1.04595272 -1.41158457 0.258708 0.26613097]
[-1.63587728 -1.04595272 -1.41158457 1.05376184 0.32134727]
[-1.60838355 -1.04595272 -1.12143831 -1.67213706 -1.05566218]]
데이터 스코어 매기기?
이제 스케일화된 데이터를 기반으로 훈련을 합니다.
기존의 훈련 방법과 똑같습니다.
바뀐 것은 훈련과정에 훈련용데이터 대신 훈련용데이터_스케일이 사용된 것 뿐이지요.
from sklearn.linear_model import LinearRegression
선형회귀모델 = LinearRegression()
선형회귀모델.fit(훈련용데이터_스케일, 훈련용목표)
지난 내용에는 없었지만, 사실 이렇게 훈련과정에 대한 척도를 평가할 수 있는 방법이 있습니다.
바로 score() 이라는 메소드인데요.
아래와 같이 사용할 수 있습니다.
print("훈련용모델 정확도")
print(선형회귀모델.score(훈련용데이터_스케일, 훈련용목표))
print("테스트모델 정확도")
print(선형회귀모델.score(테스트데이터_스케일, 테스트목표))
음? 그런데 훈련용데이터의 예측 점수보다 테스트 데이터의 예측 점수가 더 높군요?
머신러닝 서적에서는 이러한 결과를 '과소적합'이라고 하는데요.
훈련데이터가 적은 경우 발생할 수 있다고 합니다. 뭐 오늘은 넘어가도록 합시다.
훈련용모델 정확도
0.5872217352485853
테스트모델 정확도
0.730782898221902
하여간 이렇게 스케일화된 데이터를 바탕으로 예측결과를 구하고
훈련용목표예측 = 선형회귀모델.predict(훈련용데이터_스케일)
테스트목표예측 = 선형회귀모델.predict(테스트데이터_스케일)
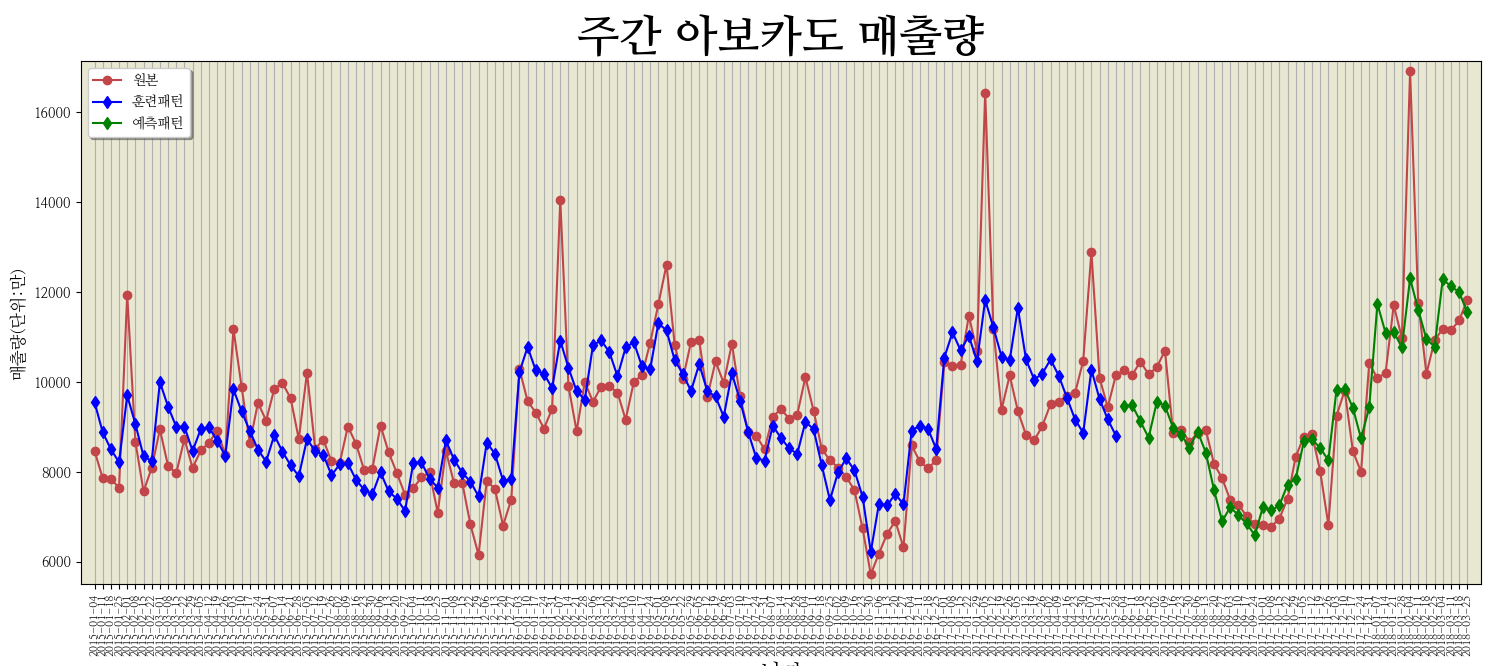
그래프로 최종결과를 출력한 바로 아래 이미지입니다.
그래프를 보자 '와우!'라는 탄성이 절로 나왔었지요 :)
오른쪽 녹색선이 머신러닝이 예측한 결과이고, 빨간선이 원본이거든요.
이 정도면 진짜 '와우~' 소리가 나올 법도 합니다.
최종 소스
이 번 예제의 결과물은 아래 URL에서 확인가능하며,
http://dreamplan7.cafe24.com/pyscript/py10-3.html
전체소스는 아래와 같습니다.
common.py 파일은 지난 게시글에서 다루었기 때문에 지난 게시글을 참조해 주세요.
<html>
<head>
<link rel="stylesheet"
href="https://pyscript.net/alpha/pyscript.css" />
<script defer
src="https://pyscript.net/alpha/pyscript.js"></script>
<py-env>
- pandas
- matplotlib
- seaborn
- scikit-learn
- paths:
- ./NANUMMYEONGJO.TTF
- ./NANUMMYEONGJOBOLD.TTF
- ./common.py
</py-env>
</head>
<body>
<link rel="stylesheet" href="pytable.css"/>
<py-script>
import pandas as pd
from pyodide.http import open_url
from common import *
import numpy as np
from datetime import datetime
# 경고 문구 제거
import warnings
warnings.filterwarnings( 'ignore' )
# 판다스에서 csv 를 데이터 프레임으로 읽어옴
매출데이터 = pd.read_csv(open_url(
"http://dreamplan7.cafe24.com/pyscript/csv/avocado.csv"
))
# 3개 필드만 추려서 데이터 프레임을 다시 만듬
매출데이터 = 매출데이터[[
'Date',
'Total Volume',
'AveragePrice'
]]
# 영문 제목을 한글로 변경
매출데이터.columns = [
'날짜',
'매출량',
'평균가격'
]
주간매출_매출량=매출데이터.fillna(0) \
.groupby('날짜', as_index=False)[['매출량']].sum() \
.sort_values(by='날짜', ascending=True)
주간매출_평균가=매출데이터.fillna(0) \
.groupby('날짜', as_index=False)[['평균가격']].mean() \
.sort_values(by='날짜', ascending=True)
주간매출데이터=pd.merge(주간매출_매출량, 주간매출_평균가, on='날짜')
# 날짜(시간값) 추가
주간매출데이터.insert(1, '날짜(시간값)',
'',
True)
for i in 주간매출데이터['날짜'].index:
주간매출데이터['날짜(시간값)'].loc[i]=time.mktime(
datetime.strptime(
주간매출데이터['날짜'].loc[i],
'%Y-%m-%d'
).timetuple()
)
# 10000으로 나눈 매출량 필드 추가
주간매출데이터.insert(3, '매출량(만)',
주간매출데이터['매출량']/10000,
True)
# 훈련학습용으로 날짜를 연도, 월, 일로 나눈다
주간매출데이터.insert(4, '연도', '', True)
주간매출데이터.insert(5, '월', '', True)
주간매출데이터.insert(6, '일', '', True)
주간매출데이터.insert(7, '주', '', True)
for i in 주간매출데이터['날짜'].index:
임시=str(주간매출데이터['날짜'].loc[i]).split('-')
연도=int(임시[0])
월=int(임시[1])
일=int(임시[2])
주간매출데이터['연도'].loc[i]=연도
주간매출데이터['월'].loc[i]=월
주간매출데이터['일'].loc[i]=일
주간매출데이터['주'].loc[i]=str(
datetime(연도, 월, 일).isocalendar()[1]
)
createElementDiv(
document,
Element,
'output2'
).write(주간매출데이터)
주간매출데이터훈련_넘파이 = 주간매출데이터[['날짜(시간값)', '연도', '월', '일', '주', '평균가격']].to_numpy()
주간매출데이터목표_넘파이 = 주간매출데이터['매출량(만)'].to_numpy()
from sklearn.model_selection import train_test_split
훈련용데이터, 테스트데이터, 훈련용목표, 테스트목표 = \
train_test_split(
주간매출데이터훈련_넘파이,
주간매출데이터목표_넘파이,
random_state=100,
shuffle=False)
#print(훈련용데이터[0:5])
#print(훈련용목표[0:5])
#print(테스트데이터[0:5])
#print(테스트목표[0:5])
#quit()
from sklearn.preprocessing import StandardScaler
스케일러 = StandardScaler()
스케일러.fit(훈련용데이터)
훈련용데이터_스케일 = 스케일러.transform(훈련용데이터)
테스트데이터_스케일 = 스케일러.transform(테스트데이터)
# 선형 회귀 알고리즘
# 훈련, 최적의 그래프를 찾아준다
from sklearn.linear_model import LinearRegression
선형회귀모델 = LinearRegression()
선형회귀모델.fit(훈련용데이터_스케일, 훈련용목표)
# 종류가 목표가 아닌 이상 정확도는 측정 불가
print("훈련용모델 정확도")
print(선형회귀모델.score(훈련용데이터_스케일, 훈련용목표))
print("테스트모델 정확도")
print(선형회귀모델.score(테스트데이터_스케일, 테스트목표))
훈련용목표예측 = 선형회귀모델.predict(훈련용데이터_스케일)
테스트목표예측 = 선형회귀모델.predict(테스트데이터_스케일)
import matplotlib.pyplot as plt
import matplotlib.font_manager as fm
import matplotlib as mat
# 기준 폰트 변경 : legend 의 한글을 적용하려면 필수
fm.fontManager.addfont('./NANUMMYEONGJO.TTF') # 폰트명 : NanumMyeongjo
mat.rc('font', family='NanumMyeongjo')
###################
# 폰트 목록 출력 ( 폰트 추가 후 정확한 이름을 확인하려면 필요
#font_list = [font.name for font in fm.fontManager.ttflist]
#for f in font_list:
# print(f)
###################
# 개별 폰트 적용
NanumMyengjo = fm.FontProperties(
fname='./NANUMMYEONGJO.TTF'
)
NanumMyengjoBold = fm.FontProperties(
fname='./NANUMMYEONGJOBOLD.TTF'
)
# 그래프
fig = plt.figure(
figsize=(15, 7)
)
plt.xticks(
주간매출데이터['날짜(시간값)'].to_numpy(),
주간매출데이터[['날짜']].to_numpy()[:,0],
rotation=90, fontsize=8)
plt.title('주간 아보카도 매출량',
fontproperties=NanumMyengjoBold,
fontsize=32
);
plt.plot(
훈련용데이터[:,0],
훈련용목표,
marker='o',
color='#c14549',
label='원본'
)
plt.plot(
훈련용데이터[:,0],
훈련용목표예측,
marker='d',
color='blue',
label='훈련패턴'
)
plt.plot(
테스트데이터[:, 0],
테스트목표,
marker='o',
color='#c14549'
)
plt.plot(
테스트데이터[:, 0],
테스트목표예측,
marker='d',
color='green',
label='예측패턴'
)
plt.xlabel('날짜', fontsize=16)
plt.ylabel('매출량(단위:만)', fontsize=12)
# loc : 표 하단 중앙
#plt.legend(
# loc=8
#)
plt.legend(
shadow=True
)
ax = plt.gca()
# 축만 그리드
ax.xaxis.grid(True)
# 배경색, 마진 조정
ax.set_facecolor('#e8e7d2')
ax.margins(x=0.01, y=0.02)
# 주위 이상한 여백 없애기
fig.tight_layout()
fig
</py-script>
</body>
</html>
마무~리
이번에는 머신러닝이 매출량 결과치를 예측하는 정확도를 높이기 위해 '평균가격'이라는 요소를 추가해보았습니다. 평균가격을 예측할 수는 없겠지만 적어도 평균가격을 이 정도로 한다면 매출량이 어느정도가 될 것이다라는 것을 예측할 수 있게 된 것이지요.
그리고 데이터 프레임을 그룹지을 때, 평균으로 그룹 짓는 방법과 2개의 데이터 프레임을 합치는 부분,
데이터를 스케일화하여 데이터 안정성을 높이는 방법을 살펴보았습니다.
아무쪼록 필요하신 분께 도움이 되셨을지요 :)
방문해주시는 모든 분들께 늘 감사드립니다.
유익하셨다면 공감 한방, 댓글은 굿잡!
감사합니다~
다음 게시글 : https://itadventure.tistory.com/555
파도!(14) - 릿지 리그레션으로 정확도가 높아진다구?
※ '파도'는 파이스크립트 도전기의 준말입니다. 지난 게시글에 연재되는 글입니다 : https://itadventure.tistory.com/554 파도!(13) - 음? 인공지능 적중율이?! - 평균가격 추가 '파도'는 파이스크립트 도전
itadventure.tistory.com
'코딩과 알고리즘' 카테고리의 다른 글
| 파도(16) - 파이스크립트의 특좌앙~점으로 머신러닝! (9) | 2022.08.19 |
|---|---|
| 파이썬3 - 기초요약 (PDF 3페이지) (9) | 2022.08.15 |
| 파도!(8) - 아보카도 판매량 (1) | 2022.07.24 |
| 파이스크립트 도전기(6) - 인터프리터(2편) (6) | 2022.07.19 |
| 파이스크립트 도전기(5) - 브라우저에서 파이썬 인터프리터? (2) | 2022.07.18 |



